Academics should care about data security on the web
It is important that we start to take security seriously. I will try to avoid making this blog post into a rant against academia. I would be the first to admit that I was not always so security aware, I would create code that would enable XSS, SQL injection or cookie hijacking. The reason? I always thought it could never happen to me, who would care about an academic research project website?
Thankfully, to my knowledge, the projects were never the victim of any breach. I did always spend time reviewing the logs. However, over the last couple of years I have become very security aware and genuinely interested in the field, and not just because of recent hacks against TalkTalk, Tesco Bank and Yahoo (x2 for this one). I have taken an active interest in security methodology and best practice when it comes to design, development, implementation and storage. I have yet to come across a degree in the UK that teaches this to a suitable standard, so I understand why our graduates may struggle in industry.
Side note: I would highly recommend you follow Troy Hunt; he is a security research who blogs about this kind of stuff.
I am going to focus specifically on web-facing infrastructure and touch on some key aspects briefly; a future article will discuss issues with storing data in academia and issues with outsourcing. This blog post does not focus directly on research projects hosted and managed by the university itself, but those that are hosted externally.
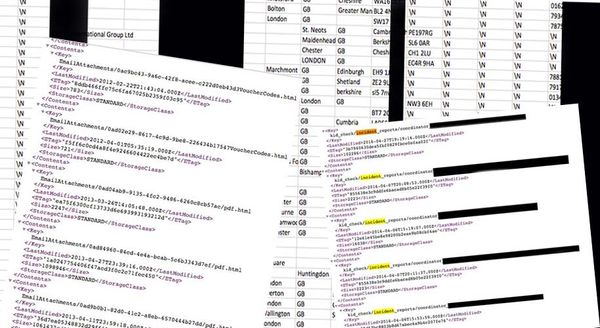
Over the last few years, "Internet of Things" and "Digital Health" have become buzzwords amongst academics, with universities focusing research efforts in this domain. With this uptake, I have become aware of multiple attack vectors which are very basic but could leak valuable data: from lack of HTTPS on registration/login, open databases (seriously!) and outdated software which has zero day vulnerabilities.
Academic research projects collect a lot of highly sensitive data on individuals, at-risk groups and adolescents (just to name a few). This information is not being adequately protected, because they are hosted on public facing directories that do not employ adequate safeguards, controls or active monitoring as standard. This is most likely due to a lack of expertise in this area.
It is important not to solely blame the academics. In many cases, the infrastructure has been outsourced and developed by “professional” companies/developers. This outsourcing of key infrastructure related to research projects is a major issue in academia, and includes the entire technology pipeline from website to data collection methods, data storage and analysis. However, it does not remove the blame from the academic/institution who has commissioned the work.
Use HTTPS
Many websites do not use HTTPS as standard. For those not aware, HTTPS stands for Hyper Text Transfer Protocol Secure, the protocol over which data is sent between your browser and the website that you are connected to. It means all communications between your browser and the website are encrypted. It is free and easy to use, services such as CloudFlare and LetsEncrypt are available.
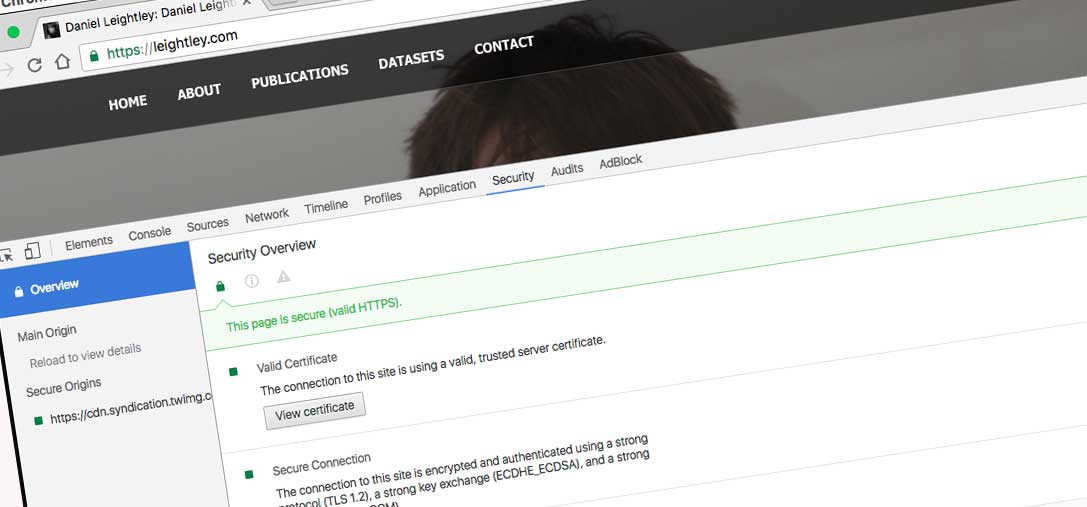
There are some negatives to enforcing HTTPS, e.g. users with old browsers may not be able to access your site. However, this number is tiny and the reward both in terms of security and perceptions of security far outweigh the benefit to these users. When you visit leightley.com you will notice that I enforce HTTPS as standard:
But many university sites and research project sites do not force HTTPS as standard. Consider the following:
- HTTPS protects the integrity of your website: A site that is transmitted over HTTPS is protected from middlemen injecting adverts or other code into the site. This means that the user gets the experience you intended and your integrity is protected.
- HTTPS protects the privacy and security of your users: Middlemen are not able to passively monitor your traffic. Insecure HTTP traffic can leak passwords, card details and other highly personal data.
- HTTPS is the future of the web and Internet of Things: Google uses the HTTP status to rank websites in its search listings. Google Chrome is moving to a more secure environment and will require full HTTPS otherwise they will display error messages to the user. Read more about this here.
In summary, it is quick, free and easy to implement HTTPS on any website, including automating the certificate renewal process. Simply, no excuse.
Maintain or take down
We have all been involved in a project that has come to an end, but we want to ensure there remains a legacy so we leave the website and any demonstration apps online. However, leaving a project site online and failing to ensure the software is updated could result in vulnerabilities being exploited. It is important to have a plan in place to ensure the project site in maintained and updated. If you do not have the ability or the skills, I would recommend taking it down or removing confidential information from the site.
Consider your data requests
It is very important to only request information that you actually need. I speak to a lot of people who collect as much data as they can, then try to determine the research question/solution around the data. It should be the other way round, only collect the information that you absolutely need to answer your research question. You do not need to ask for their name and address if all your interested in is gender. Why does this matter? The more information you collect about an individual, the more identifiable, personal and valuable it becomes. Using first name, last name, a security question and date of birth I could take over a persons Amazon account.
If you have to collect this information, ensure that you use the appropriate data storage policies and encryption.
Be proactive
I recently had to contact an academic who had a research project that was active via a standalone website. Undertaking a basic investigation on the whois data I was able to determine that it was in-fact hosted externally and by a third party developer.
They were not using HTTPS on the site but were asking for sensitive information such as username, password and some highly sensitive data related to the research they were undertaking.
I politely informed them that it was standard practice that sites requiring personal information such as login use a HTTPS connections. I provide some suggestions such as CloudFlare.
The second issue I had was with the servers they were operating on. The response header was returning a lot of information (more than usual) about the server setup, software versions and databases. I again informed them the importance of maintaining the project with regular updates and patches. The major concern I had was that the server had not been updated in some time, which several major security notices.
I sent the email in the hope of getting a reply. They kindly followed up, including a response from the developer detailing the actions taken. The interesting aspect of the exchange was the request, I was asked to provide guidance on if the developer had adequately protected the site.
I was happy to see them being so proactive, but a little concerned with the trust placed in me to verify the security vulnerabilities had been patched to a suitable standard.
What can we do in academia?
Take security seriously, and not just for the ethics application. Any content that is publicly accessible is vulnerable. Plan for maintenance and cost it into the budget. Following basic security principles are not different, nor do they cost any money.
Update 1 (18/12/2016): I have made some changes to the post to provide greater clarity.